





I. Avant de commencer…▲
Pour mettre en pratique ce tutoriel, nous avons au minimum besoin de :
- une base de données (IBM® DB2® pour LUW, Microsoft® SQL Server, Oracle® et/ou Sybase®) ;
- les clients associés aux bases de données utilisées ;
- Embarcadero Change Manager Ultimate Edition (Masquage des données uniquement disponible dans cette édition) ;
- un poste de travail (500 Mo d'espace disque, 1 Go de mémoire) (Informations complémentairesEmbarcadero Change Manager System Requirements).
Concrètement, nous allons utiliser :
- une base de données Oracle 10g ;
- Client pour Oracle 10g ;
- une base de données Microsoft SQL Server ;
- Client natif pour Microsoft SQL Server ;
- Embarcadero Change Manager Ultimate Edition avec une version d'évaluation de 14 jours.
Il existe quatre éditions différentes d'Embarcadero Change Manager : Personal, Standard, Professional & Ultimate.
Les différences entre les éditions sont décrites sur cette pageEmbarcadero Change Manager - Product Editions.
II. Téléchargement de Change Manager▲
Pour télécharger Embarcadero Change Manager, il suffit d'aller sur le site suivant : Télécharger une version d'évaluation de Change ManagerDownload a Trial for Change Manager.
Une licence d'évaluation est valide pour une durée de 14 jours à compter du téléchargement.
On clique sur le lien ![]() correspondant à son système d'exploitation ; dans ce tutoriel, on utilisera
correspondant à son système d'exploitation ; dans ce tutoriel, on utilisera ![]() Windows.
Windows.
On accepte les restrictions d'exportation (Agree), et le téléchargement se lance.
Sur la page Web, on spécifie son utilisateur EDNEmbarcadero Developer Network ou pour les nouveaux, on en crée un, afin de recevoir une licence d'évaluation :
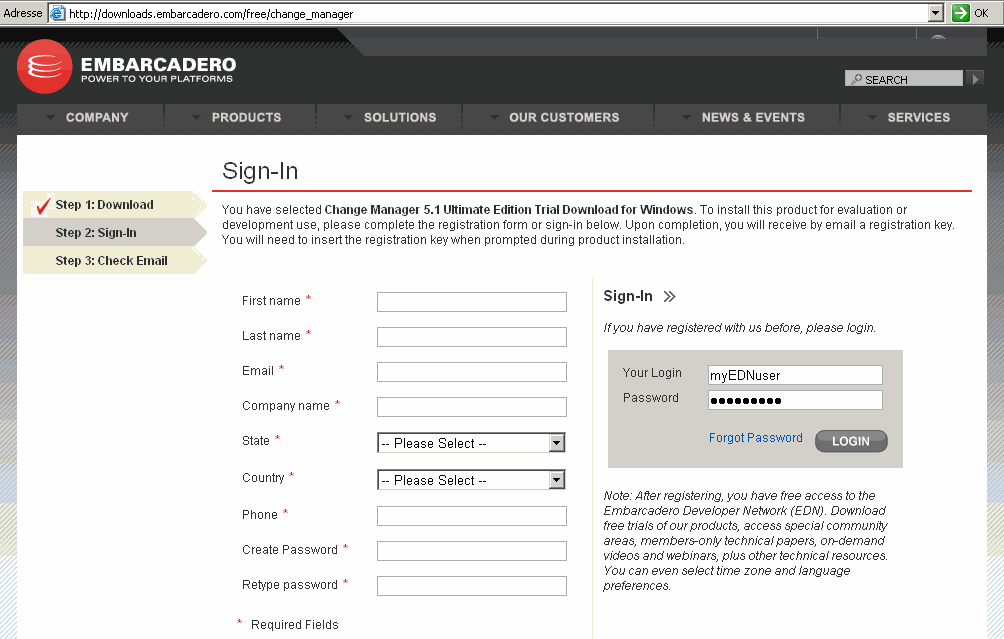
On vérifie ses emails afin de trouver un email intitulé, « Enregistrement de produit Embarcadero », envoyé par « Embarcadero-licensing [activation@embarcadero.com] ». On procède ensuite à l'installation du produit…
Certains clients de messagerie peuvent considérer cet email comme du spam et le classer dans le répertoire des courriers indésirables / spams !
Si vous ne le voyez pas arriver dans les cinq minutes, pensez à vérifier…
III. Installation de Change Manager▲
III-A. Installation des fichiers▲
Après avoir téléchargé le produit, on exécute le programme d'installation : 
InstallAnywhere décompresse les fichiers et le programme d'installation affiche son premier écran :
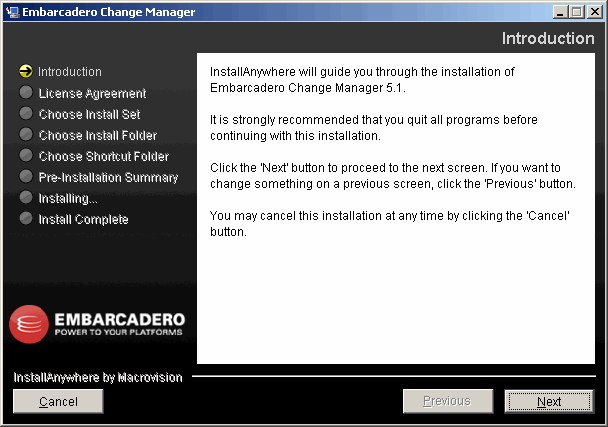
On clique sur Next :
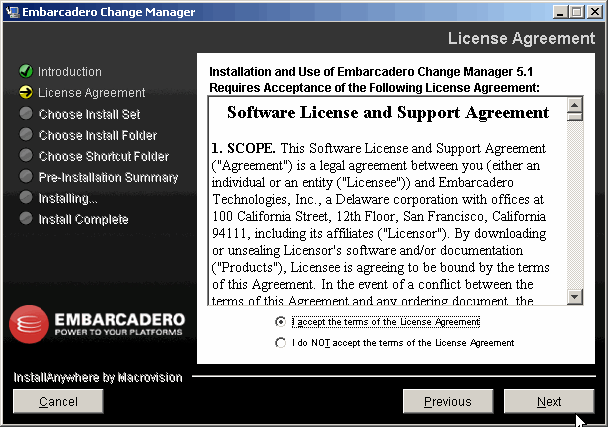
On accepte les termes de la licence, on clique sur Next :
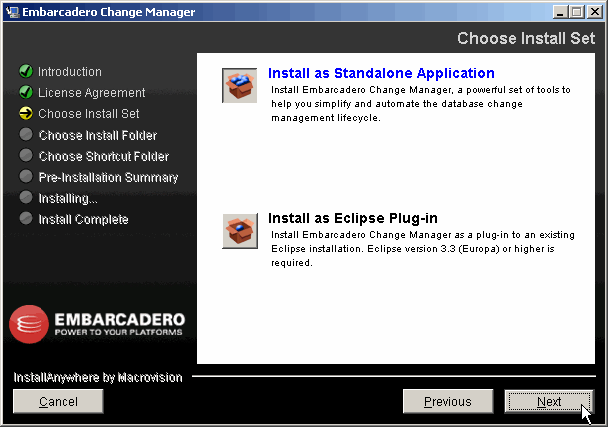
Change Manager peut s'installer de deux façons :
- Application autonome ;
- Extension dans un Eclipse existant (3.3 – Europa).
Dans ce tutoriel, on installera l'application autonome, on clique sur Next :
Après avoir choisi le répertoire dans lequel on veut installer Change Manager, on clique sur Next :
On choisit les raccourcis souhaités et on clique sur Next :
On vérifie les paramètres d'installation puis on lance l'installation en cliquant sur Install :
Une fois l'installation terminée, cet écran s'affiche :
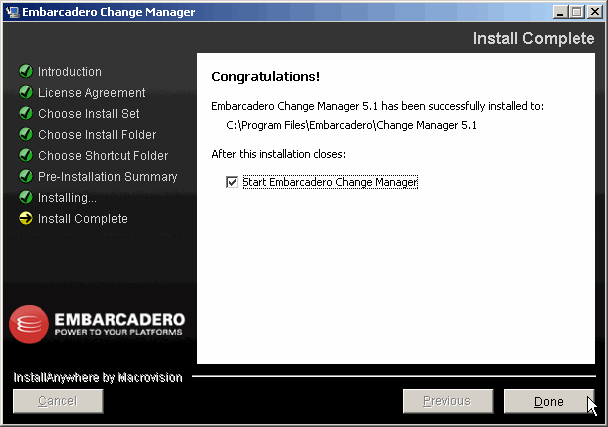
On coche la case pour lancer Embarcadero Change Manager automatiquement et on clique sur Done.
L'installation est alors terminée. On peut passer à l'enregistrement…
III-B. Enregistrement▲
Lorsqu'Embarcadero Change Manager se lance pour la première fois, un expert permettant l'enregistrement s'exécute :
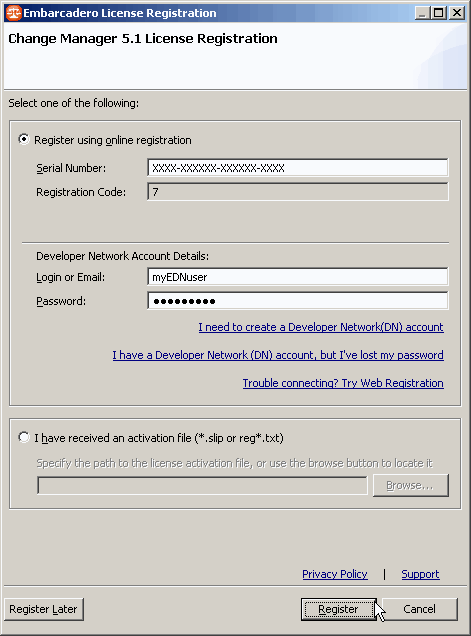
On renseigne les différents champs avec les informations reçues par email, et on clique sur Register.
L'interface d'Embarcadero Change Manager se lance…

IV. Enregistrement des sources de données▲
Avec la version 5.1, lorsque Change Manager se lance, un expert vous permet d'effectuer les tâches courantes, d'accéder très rapidement à vos précédents travaux, d'importer les sources d'une version précédente…
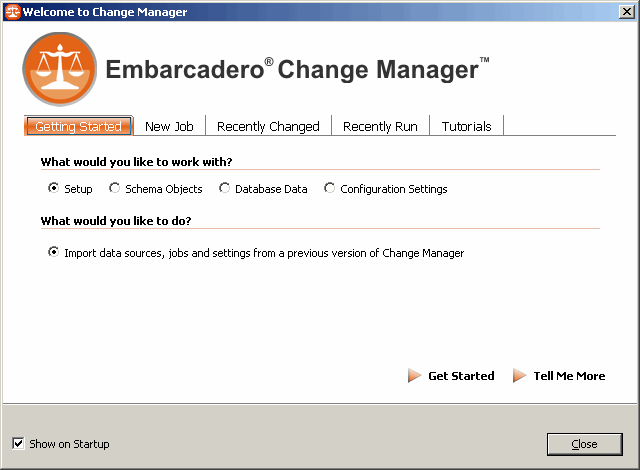
Pour ce tutoriel, nous allons manuellement ajouter deux sources de données distinctes :
- une source pour une base de données Oracle 10g de production contenant les données réelles ;
- une source pour la base de données Microsoft SQL Server utilisée par les développeurs/testeurs.
Pour manuellement ajouter nos sources de données, nous fermons l'expert de bienvenue en cliquant sur Close.
IV-A. Ajout d'une source de données Oracle 10g▲
Afin d'ajouter une nouvelle source de données, nous allons utiliser le menu contextuel du répertoire Managed Data Sources. Pour cela, on va sur l'onglet Data Source Explorer :
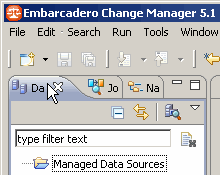
On fait un clic avec le bouton droit sur le répertoire Managed Data Sources et on clique sur New / Data Source :
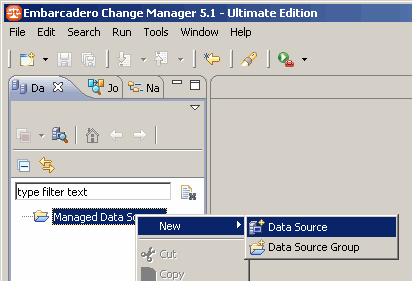
Un expert pour nous guider lors de la création de cette nouvelle source de données se lance alors. Notre base de production étant sur Oracle 10g, nous choisissons ce type de base de données.
Nous cochons également la case pour que Change Manager nous crée un répertoire par type de bases :

Les écrans suivants varient en fonction du type de bases de données choisi. On constate par exemple qu'en ayant choisi Oracle, on a le choix entre l'utilisation du TNS Name ou de renseigner directement les différentes informations :
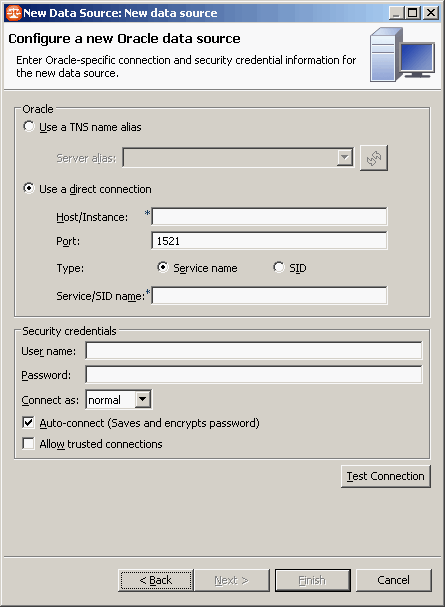
Pour accéder à un type de bases de données, le client de cette base doit être installé sur la machine qui héberge Embarcadero Change Manager (dans le cadre de ce tutoriel, un client Oracle 10g et un client Microsoft SQL Server sont installés).
On clique sur le bouton Test Connection et si vos paramètres sont correctement renseignés, vous devez obtenir cet écran :
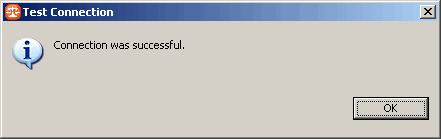
Il ne reste plus qu'à cliquer sur le bouton Finish pour finaliser la création de cette nouvelle source de données et la visualiser ainsi dans l'explorateur des sources de données :
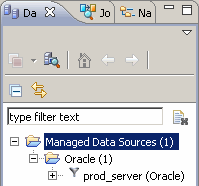
Nous pouvons maintenant procéder à l'enregistrement de la source de données Microsoft SQL Server…
IV-B. Ajout d'une source de données Microsoft SQL Server▲
Pour procéder à l'ajout de la source de données de développement, on peut procéder de la même manière que pour la première. Nous allons opérer différemment.
Nous allons cliquer sur le menu : File / New / Other…
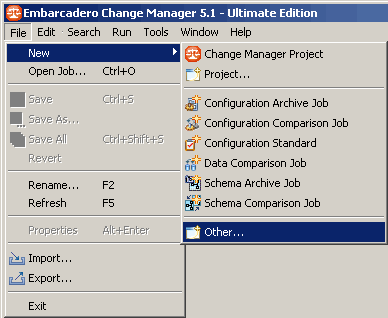
Puis nous allons choisir l'élément Data Source dans le répertoire SQL Development :
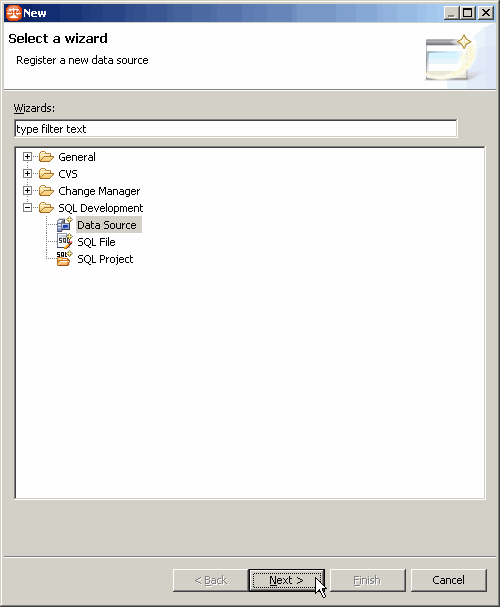
On retrouve alors le même écran que lors de l'enregistrement de la première source de données :
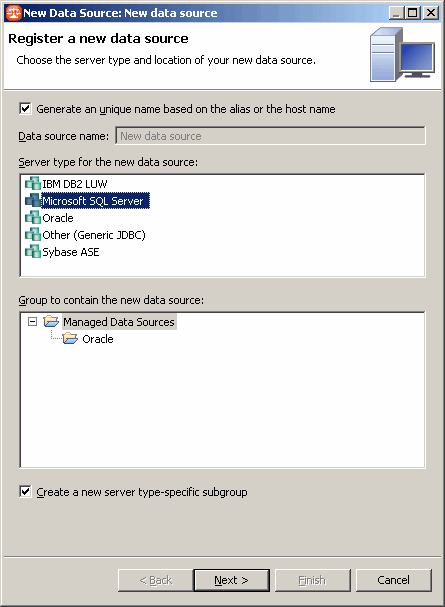
On définit les différents paramètres spécifiques à Microsoft SQL Server :
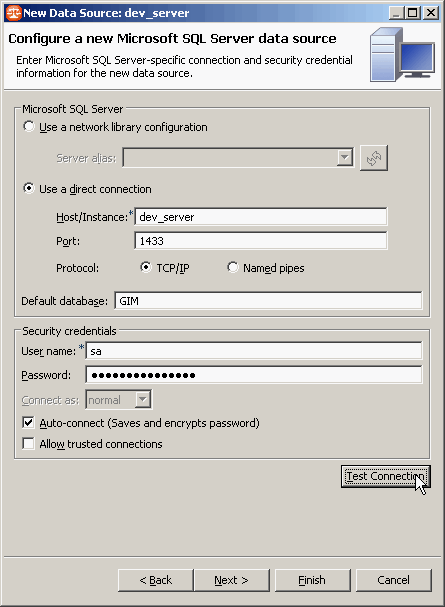
On valide que les paramètres sont corrects en cliquant sur le bouton Test Connection :
Puis on clique sur le bouton Finish pour visualiser les deux sources maintenant configurées dans Embarcadero Change Manager :
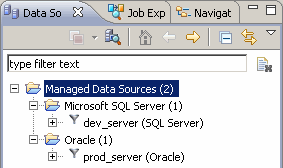
Comme j'ai coché la case pour la création d'un répertoire par type de bases, on constate la création des sous-répertoires par type de bases (Oracle et Microsoft SQL Server).
V. Paramétrage pour la création des données▲
Maintenant que nous avons configuré nos deux sources de données, nous allons créer un job afin de copier les données de notre serveur de production sur notre serveur de développement. Nous allons également paramétrer ce job afin que cette copie, ne contiennent pas de données sensibles, mais des données similaires, utilisables par les développeurs/testeurs.
Pour cela nous créons un nouveau job de comparaison des données, Data Comparison Job. De nombreuses méthodes existent pour créer un nouveau job. Nous allons le créer en utilisant le menu principal de Change Manager et en cliquant sur File / New / Data Comparison Job :
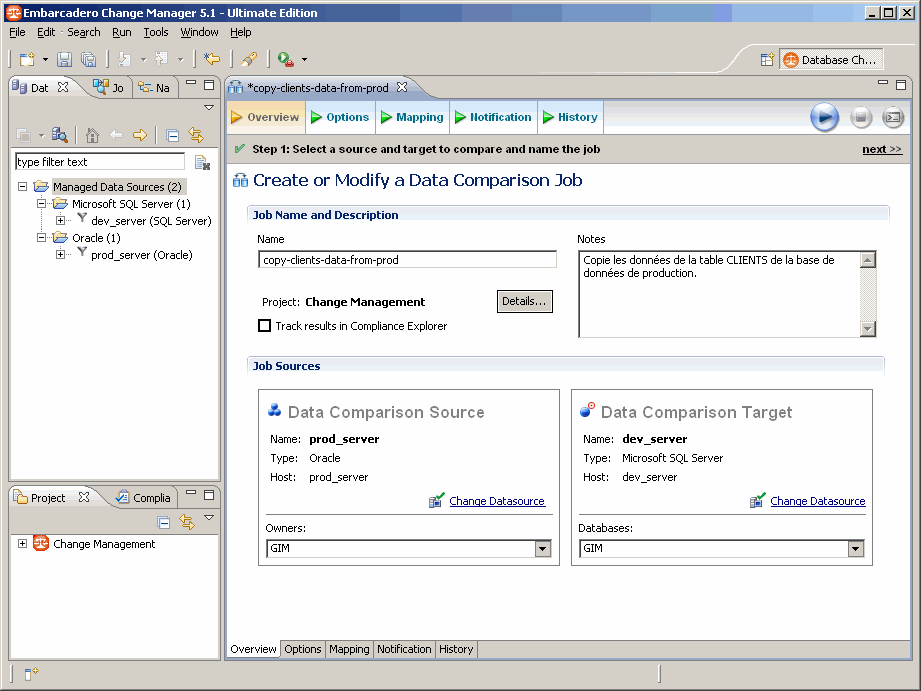
Un nouvel expert s'affiche dans la partie centrale. Il se décompose au départ en cinq parties principales : Overview (vue d'ensemble), Options, Mapping (Mappage des données), Notifications, History (Historique). Une 6e partie affichera les résultats (Results) après l'exécution du job.
On donne un nom à notre job, éventuellement une description.
Puis on spécifie les deux sources de données à utiliser ainsi que la base de données sur laquelle on souhaite effectuer le traitement (GIM dans ce tutoriel) :
On clique ensuite sur l'onglet Options.
On coche la case Automatically Synchronize qui va nous permettre, non seulement d'automatiser la synchronisation, mais également d'utiliser les règles de masquage lors de la future copie.
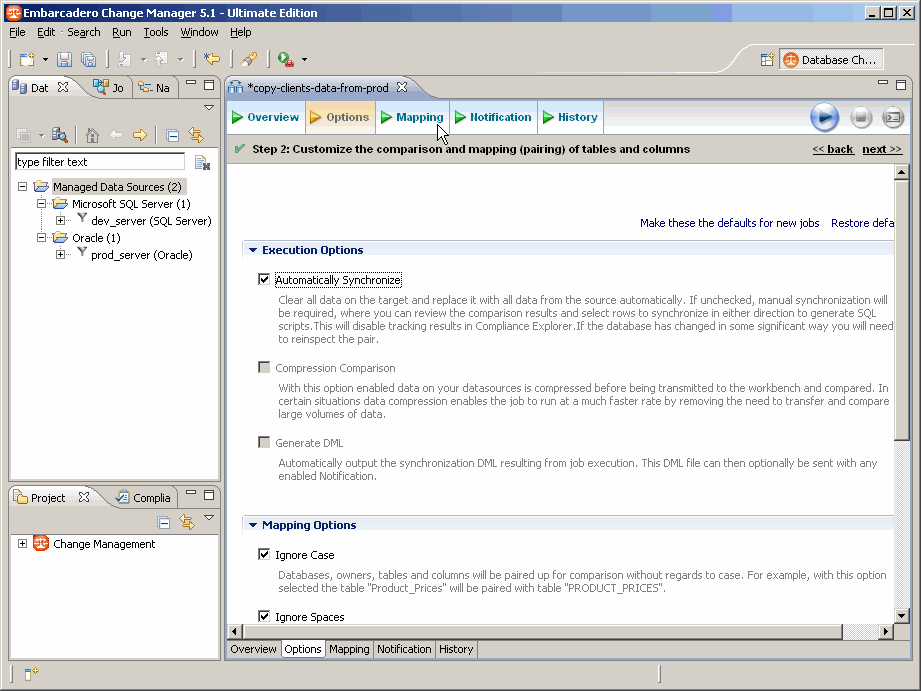
Parcourez les différentes options pour voir les possibilités proposées lors de la copie des données.
On clique ensuite sur l'onglet Mapping.
Vous pouvez ajouter d'autres bases si vous le souhaitez ou on clique directement sur celle que l'on a choisie dans le premier écran, afin de la sélectionner pour faire apparaître le lien Yes, retrieve the objects in this pair dans la seconde partie du cadre (Table Mapping) :
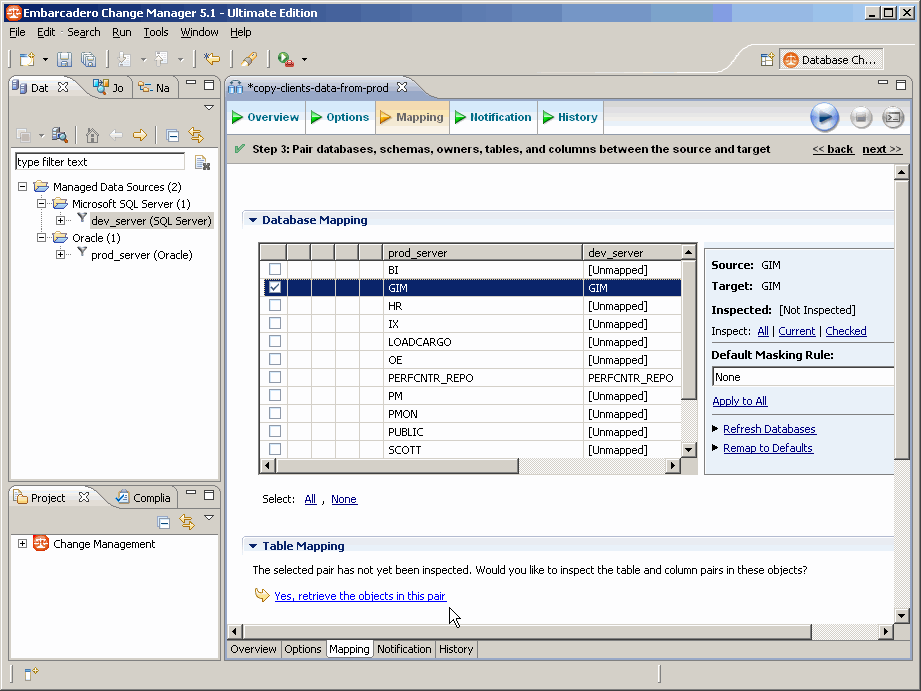
On clique sur le lien Yes, retrieve the objects in this pair et Change Manager récupère les différentes tables et les affiche :
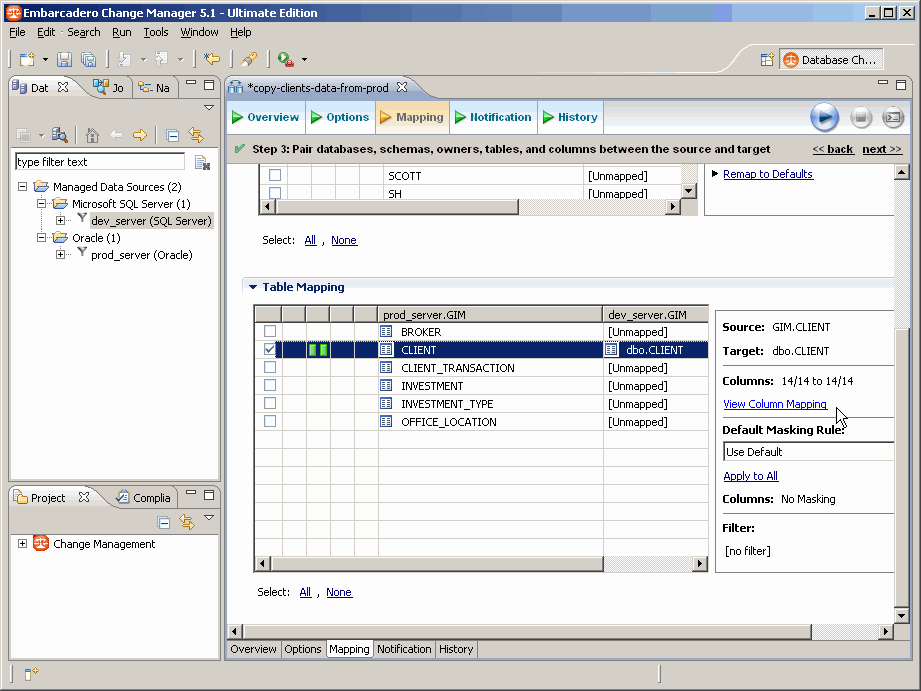
On clique sur le lien View Column Mapping pour afficher les différentes colonnes et masquer les données sensibles :
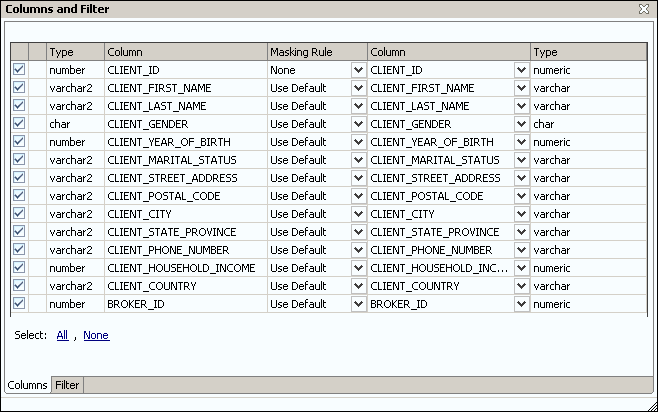
Nous choisissons de mélanger les données entre les différentes lignes de la table de production pour les prénoms et les noms dans la table de la plateforme de développement ainsi que de générer une valeur aléatoire pour les numéros de téléphone :
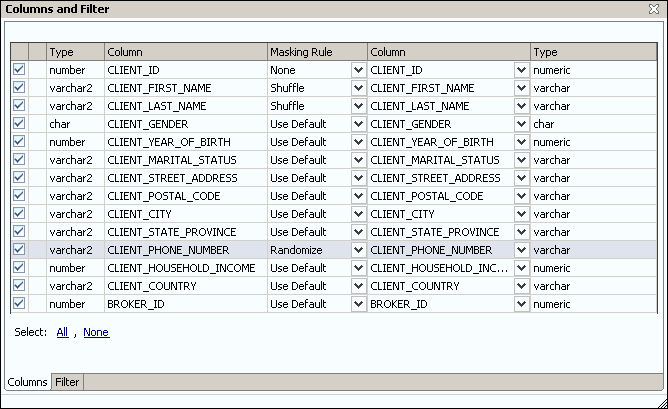

Pour le masquage des données, il existe quatre options :
- None : recopie la donnée d'origine ;
- Randomize : génère une donnée aléatoire dans le même format que les données d'origine ;
- Shuffle : mélange les lignes ;
- Use Default : utilise le paramètre de masquage défini sur la table elle-même.
Voici quelques courts exemples pour illustrer :
|
Numéro de ligne |
Source |
None |
Randomize |
Shuffle |
||
|
1 |
AAA |
AAA |
B4Z |
QP7 |
BBB |
18W |
|
2 |
BBB |
BBB |
S87 |
1D0 |
AAA |
BBB |
|
3 |
C1F |
C1F |
1S6 |
DB4 |
18W |
123 |
|
4 |
123 |
123 |
8W9 |
32D |
C1F |
AAA |
|
5 |
18W |
18W |
TY8 |
1S6 |
123 |
C1F |
|
Numéro de ligne |
Source |
None |
Randomize |
Shuffle |
||
|
1 |
123 |
123 |
423 |
612 |
789 |
334 |
|
2 |
456 |
456 |
410 |
384 |
456 |
123 |
|
3 |
789 |
789 |
231 |
619 |
124 |
456 |
|
4 |
124 |
124 |
941 |
457 |
334 |
789 |
|
5 |
334 |
334 |
651 |
314 |
123 |
124 |
|
Numéro de ligne |
Source |
None |
Randomize |
Shuffle |
||
|
1 |
123-456 |
123-456 |
845-124 |
612-941 |
123-456 |
124-951 |
|
2 |
124-951 |
124-951 |
107-035 |
384-078 |
124-951 |
123-456 |
Lorsque l'on a terminé les différents mappages, on clique sur l'onglet Notification si on souhaite être notifié lors de l'exécution du job.
Nous allons simplement paramétrer le job pour que celui-ci génère des fichiers afin que nous puissions contrôler son exécution :
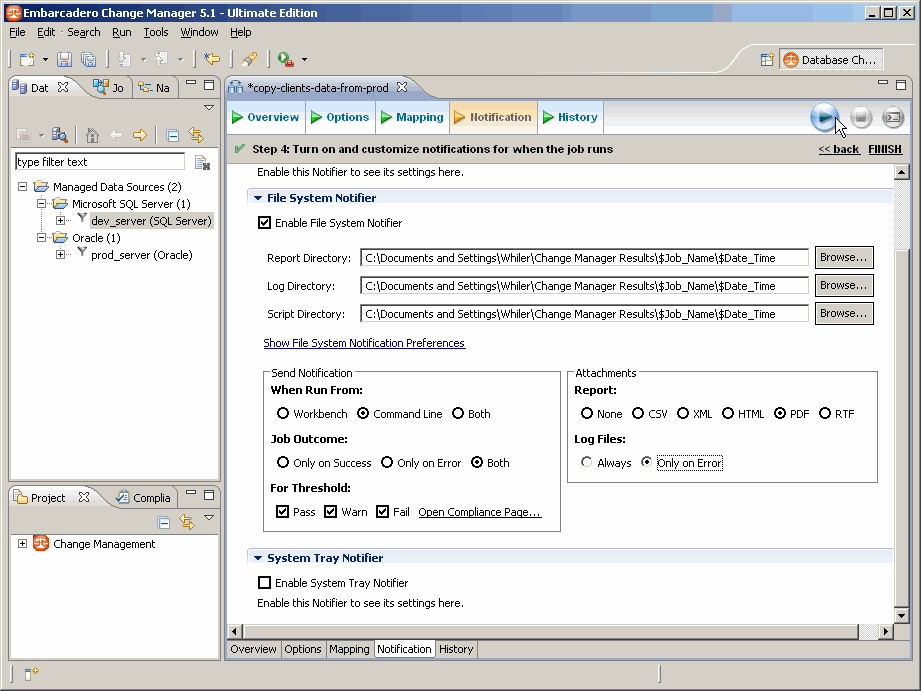
Nous demandons la génération de fichiers lorsque nous utiliserons un batch en ligne de commande uniquement, quel que soit le résultat. Les fichiers générés seront systématiquement un état sous forme de PDF, et des fichiers de logs en cas de problème.
Nous sommes prêts à générer les données sur la base de développement…
L'onglet History comporte une liste actuellement vide puisque l'on n'a encore jamais exécuté le job.
VI. Génération des données sur la base de développement▲
Pour exécuter le job que l'on vient de paramétrer, on clique sur le bouton Run Job, situé en haut à droite ![]() pour lancer la synchronisation entre les deux bases de données. Un message de confirmation vous demande de confirmer avant que toutes les données d'origine de la base de développement ne soient supprimées (dans le contexte de ce tutoriel, seule la table CLIENT est mappée, et sera donc la seule impactée) :
pour lancer la synchronisation entre les deux bases de données. Un message de confirmation vous demande de confirmer avant que toutes les données d'origine de la base de développement ne soient supprimées (dans le contexte de ce tutoriel, seule la table CLIENT est mappée, et sera donc la seule impactée) :
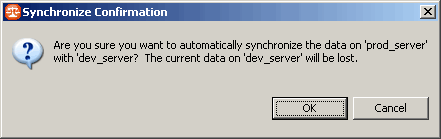
Soyez certain d'effectuer vos manipulations sur les bonnes bases de données !
Lorsque le transfert est terminé, on obtient le 6e onglet Results avec les résultats :
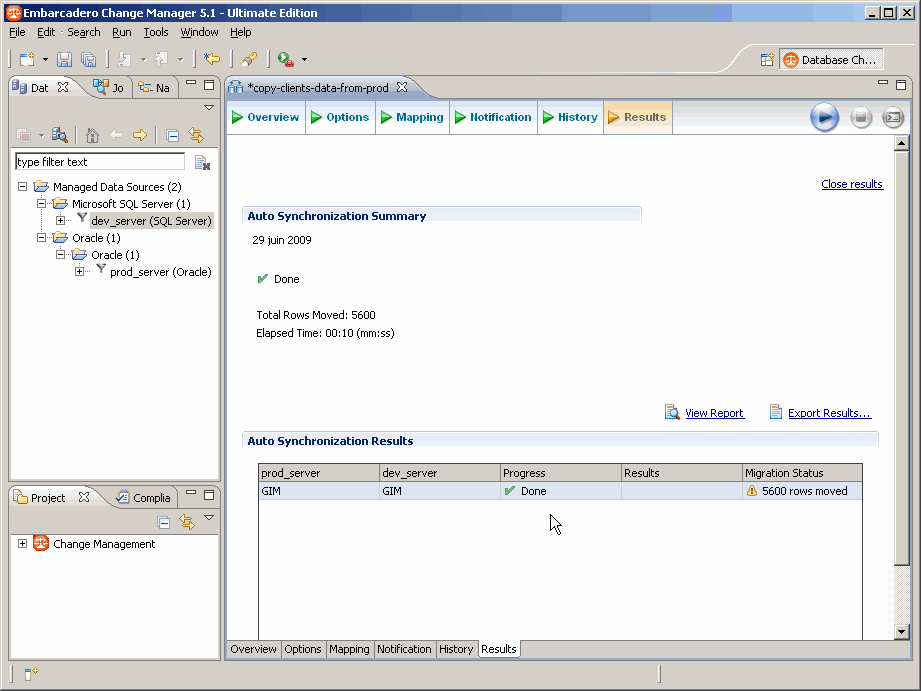
On peut cliquer sur View Report afin de générer un état :
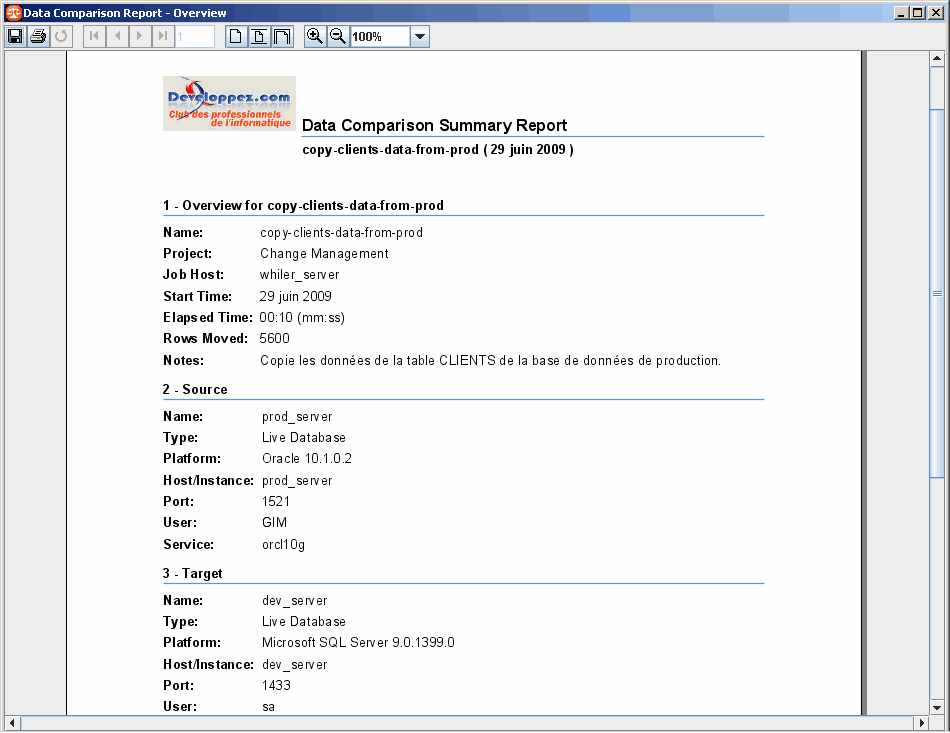
On sauvegarde le job afin de pouvoir le réutiliser ultérieurement en cliquant sur l'icône en forme de disquette de la barre d'outils ou avec le menu principal de Change Manager (File / Save) :
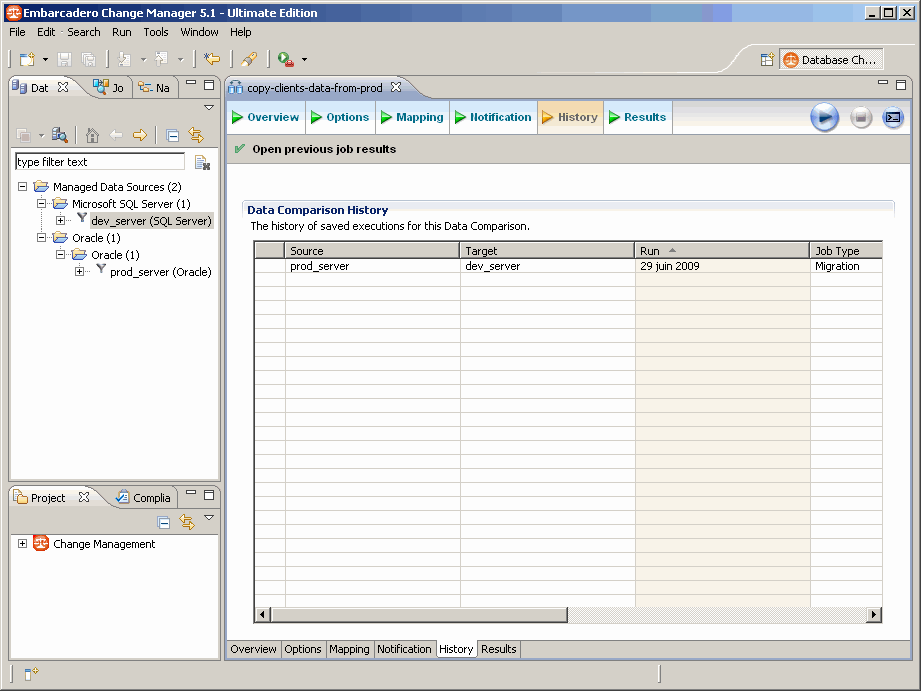
On peut alors voir notre première sauvegarde apparaitre dans l'onglet History (Historique) :
VII. Vérification des données générées▲
On a constaté dans les résultats du job que l'on vient d'exécuter que 5600 lignes avaient été générées.
Nous allons maintenant comparer les données entre ces deux bases pour visualiser les différences. Pour cela, nous allons créer un nouveau job de comparaison des données.
À partir du menu contextuel des comparaisons de données de la source de données de production, nous créons un nouveau job de comparaison des données :
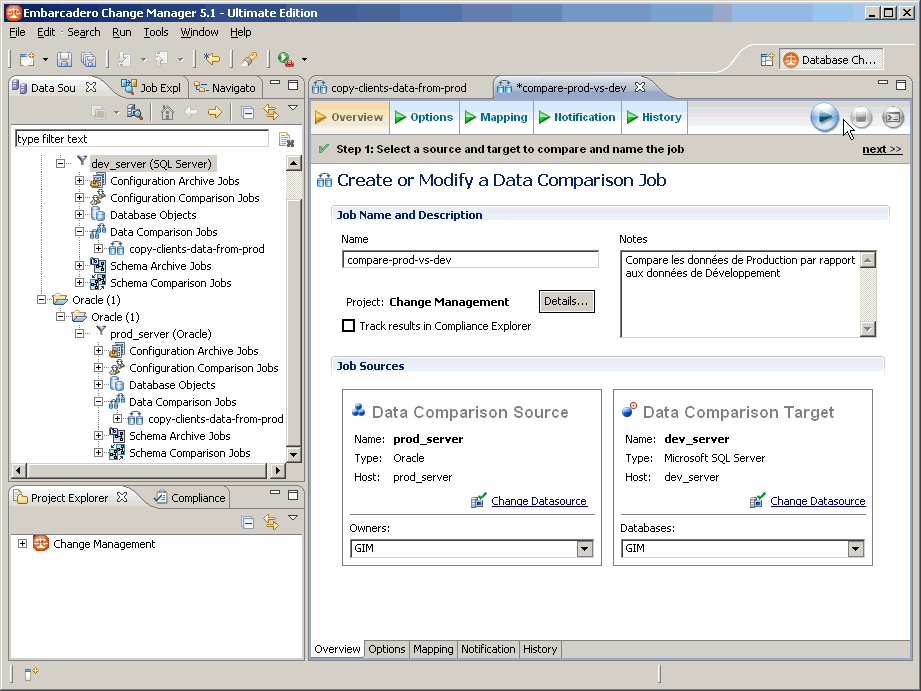
Paramétrage du job en fonction des besoins. Dans notre contexte, nous choisissons les mêmes sources de données & donnons un nom au job :
Le mappage par défaut convient et nous n'avons pas besoin de notification. Nous pouvons directement exécuter ce job et visualiser les résultats :
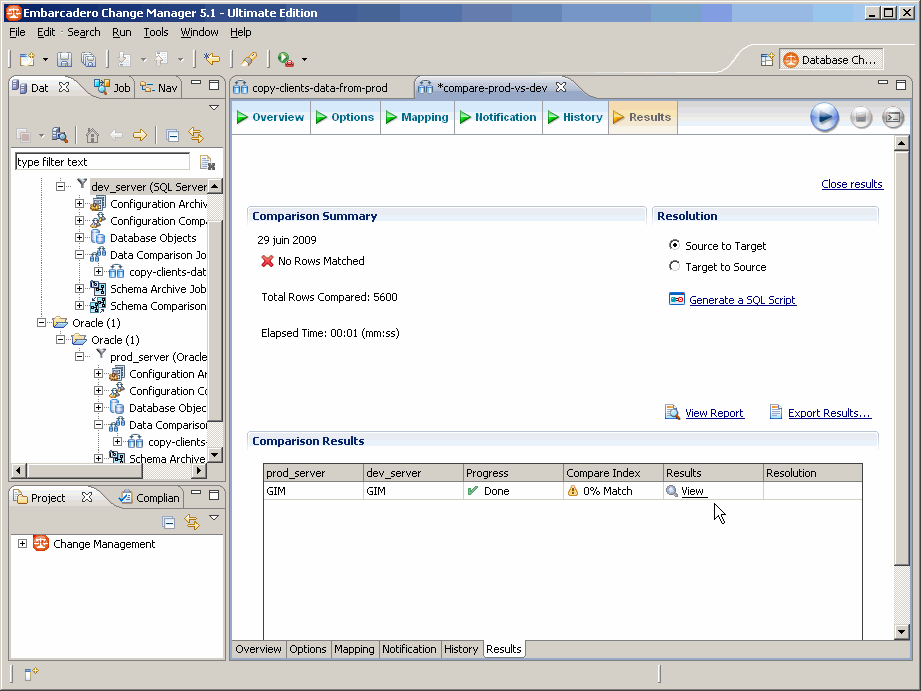
En cliquant sur le lien View, on fait apparaitre un onglet supplémentaire, Database Results. En choisissant la table que l'on avait précédemment synchronisée, on va pouvoir comparer côte à côte les lignes des deux bases de données :
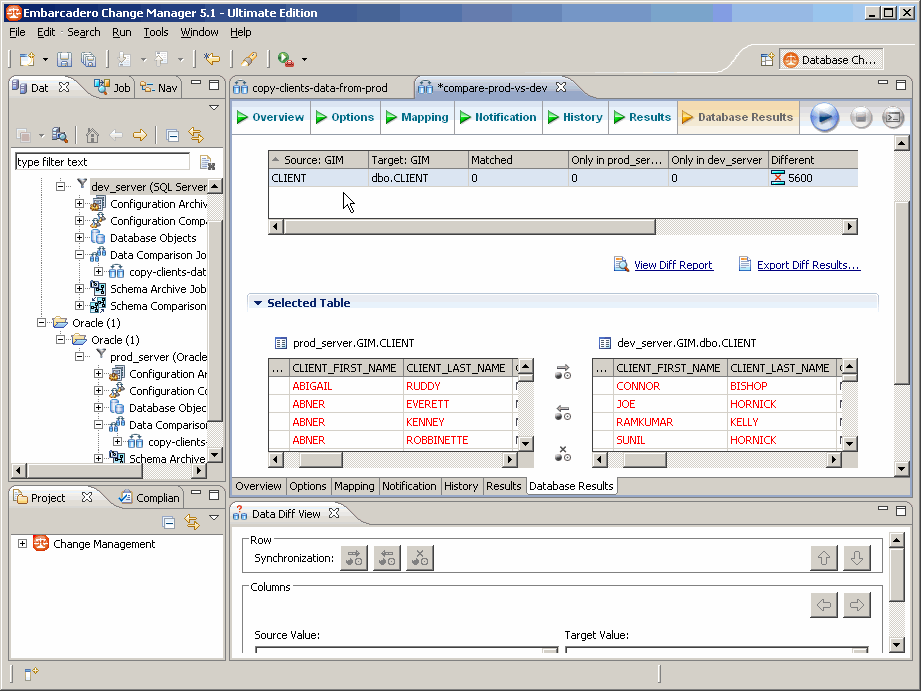
On constate que les prénoms et les noms sont mélangés, tandis que les numéros de téléphone :
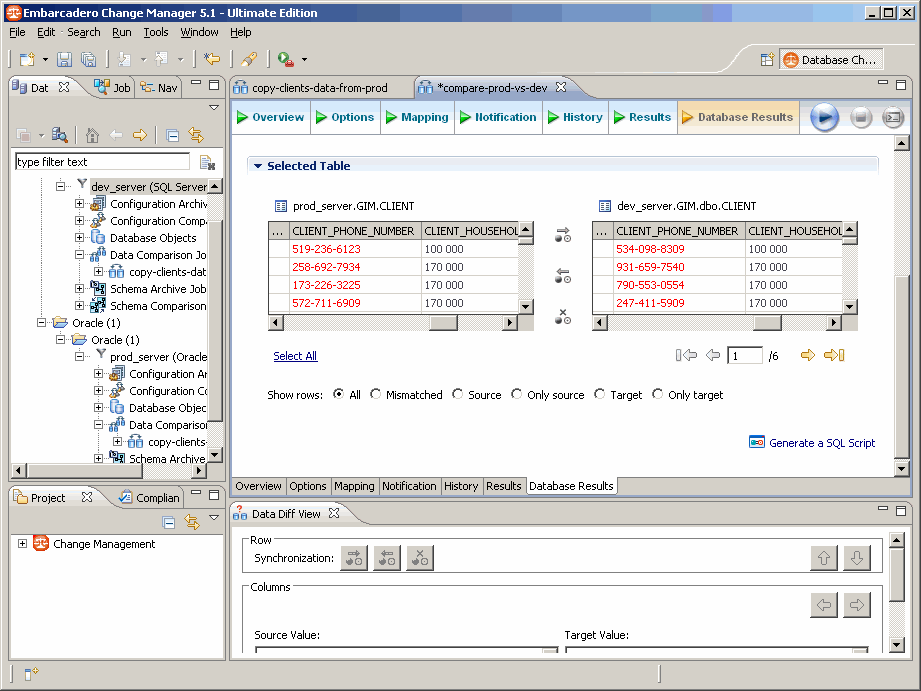
… sont complètement aléatoires.
Nos données ainsi générées pour le développement sont parfaites. Nous allons maintenant pouvoir l'automatiser afin d'avoir régulièrement des données similaires à celles de production.
Embarcadero Change Manager permet également de comparer des schémas. On pourrait par conséquent également automatiser la modification des schémas avant la synchronisation des données…
VIII. Automatisation pour une génération planifiée▲
Notre premier job a généré les données que nous attendions. Nous allons donc automatiser celui-ci.
Pour cela, nous allons générer un script que l'on pourra exécuter en ligne de commande, donc sans avoir à lancer Change Manager manuellement. Plusieurs méthodes existent pour générer ce script en ligne de commande. Lorsque le job est ouvert, on peut par exemple, cliquer sur le bouton Generate Command Line ![]() ou à partir du menu contextuel du job dans l'explorateur de job (Job Explorer) :
ou à partir du menu contextuel du job dans l'explorateur de job (Job Explorer) :
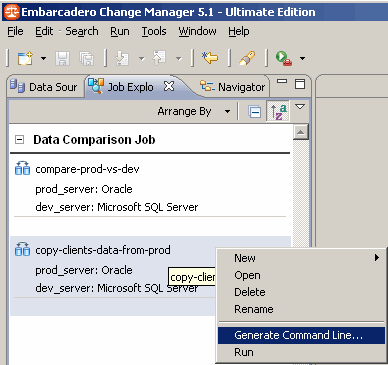
Un expert pour la génération du script se lance. Il permet de définir les états que l'on veut générer :
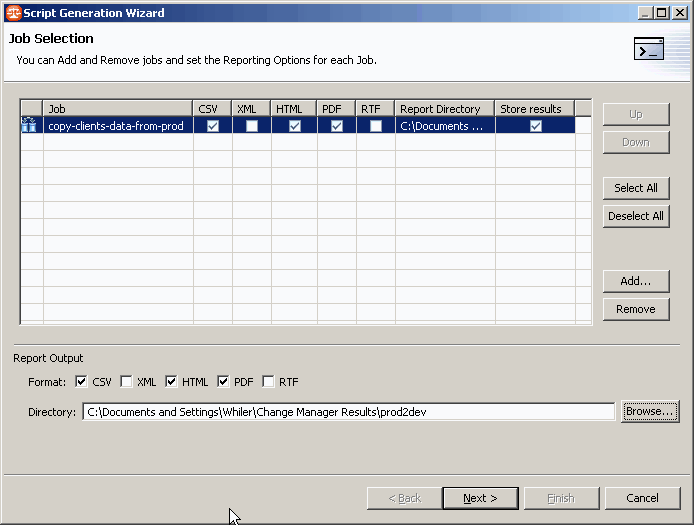
… ainsi que le fichier (Commande DOS ou ANT) :
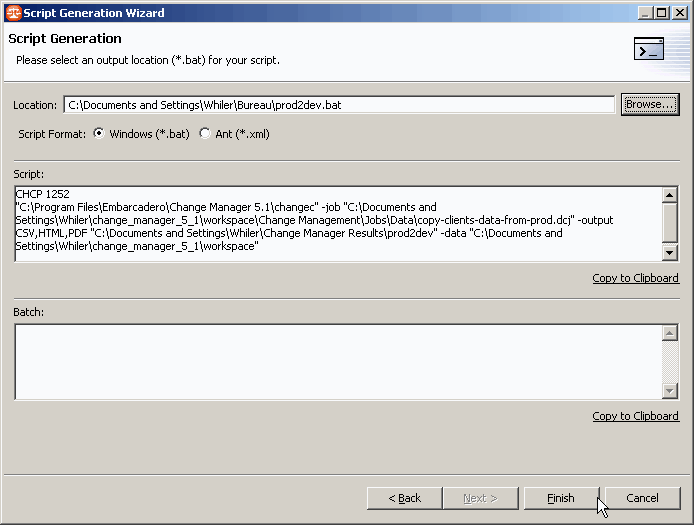
Lorsque l'on clique sur le bouton Finish, le fichier est alors généré à l'emplacement préalablement choisi :
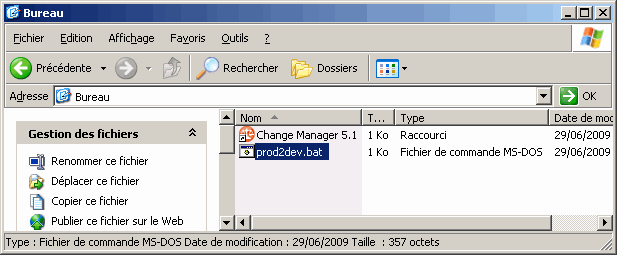
On peut automatiser ce script en le planifiant dans le planificateur des tâches de Windows par exemple.
Nous allons commencer par le tester à partir d'une invite de commande MS-DOS :
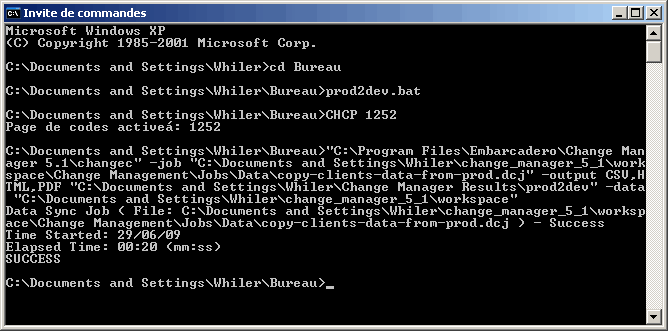
Le script s'est parfaitement déroulé. Nous pouvons vérifier également un des états que nous avons paramétré lors de la génération du script :

Une fois le script planifié pour s'exécuter à intervalles réguliers, on a terminé !
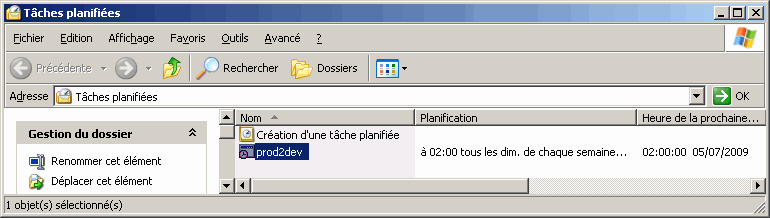
L'exécution du script en ligne de commande ne nécessite pas que l'interface de Change Manager soit lancée sur la machine.
IX. Liens utiles▲
Quelques liens pour obtenir davantage d'informations :
X. Conclusion▲
Durant ce tutoriel, nous aurons vu quelques-unes des fonctionnalités d'Embarcadero Change Manager, dont :
- création de sources de données (experts dédiés par type de source) ;
- Job pour la synchronisation des données ;
- Job pour la comparaison des données ;
- comparaison manuelle côte à côte des différences ;
- script pour la synchronisation automatique des données.
De nombreuses autres fonctionnalités tout aussi utiles sont également disponibles : pour les configurations, les schémas, l'archivage, la comparaison avec des références…
Regardez les vidéos du dernier lienwww.embarcadero.com ! Même si votre anglais n'était pas des meilleurs, les images parlent souvent d'elles-mêmes. Ce tutoriel est fortement inspiré de l'une d'elles !